Three weeks ago we released a new version of Speak Like A Brazilian.
Most changes are not visible to users, mainly improvements to the framework used to build it
(Laravel).
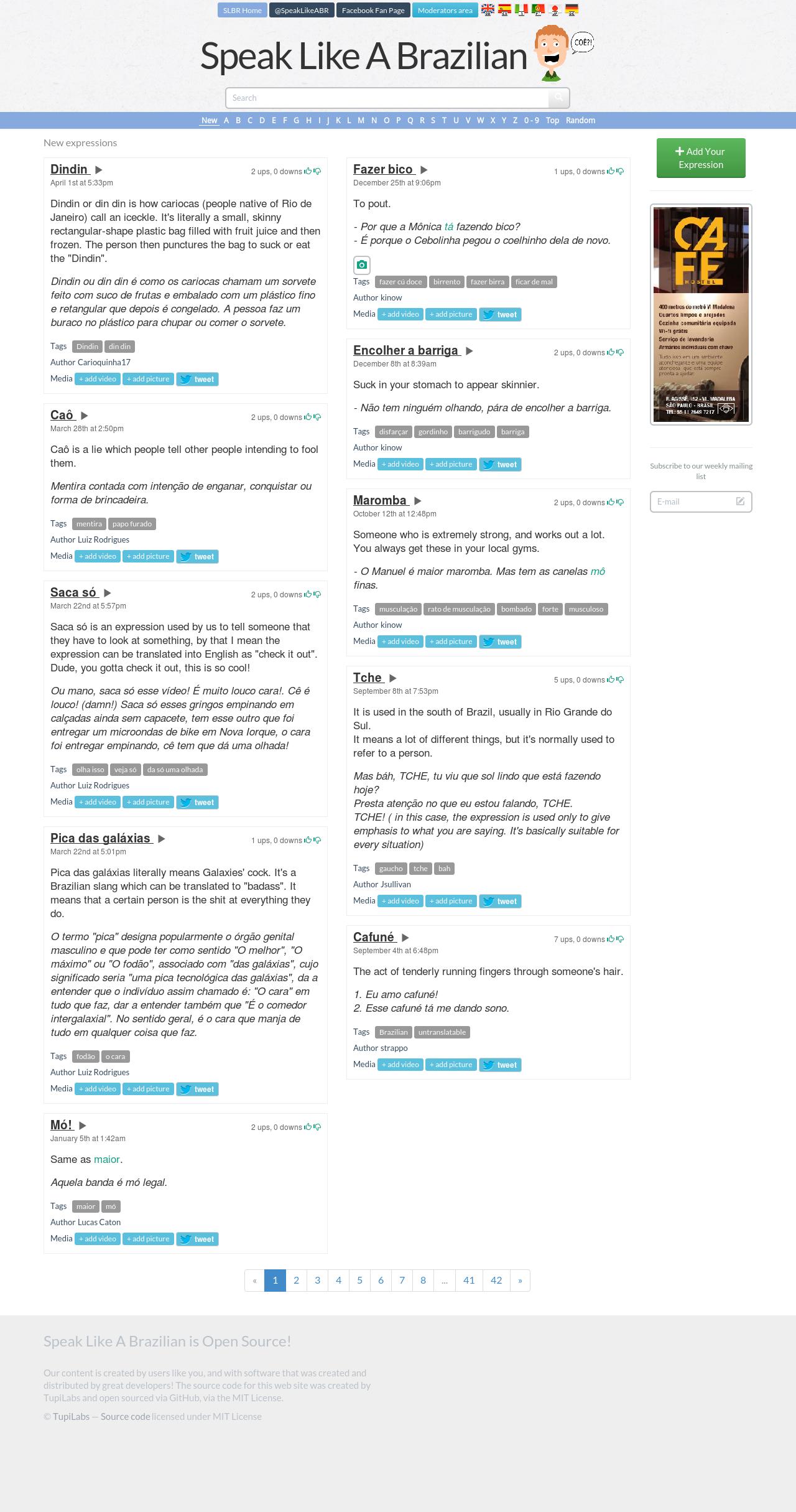
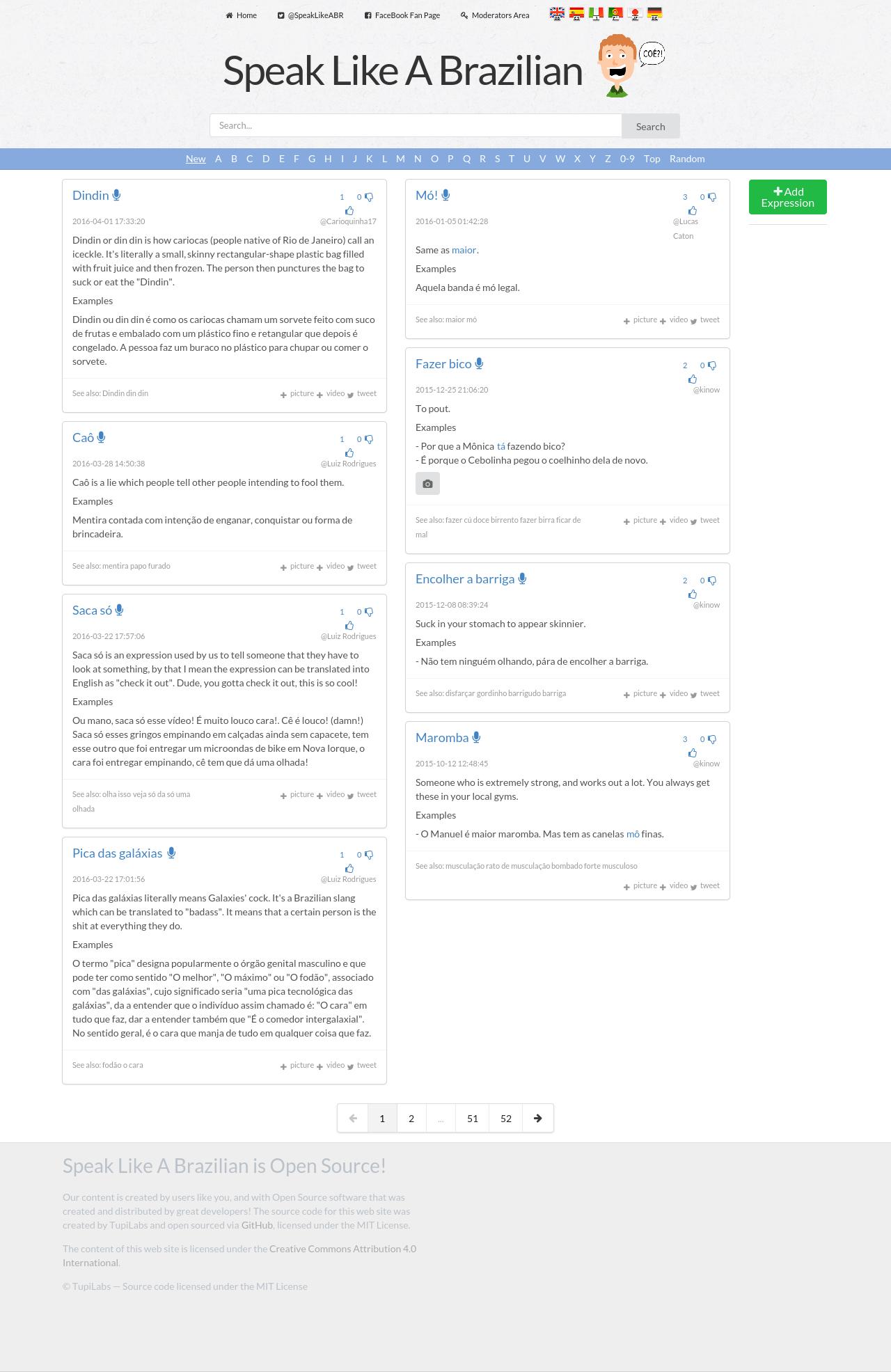
But one major change that is visible to users is the new layout and CSS, powered by
Semantic UI, which replaces Bootstrap.
Screenshot SLBR v2.1
Screenshot SLBR v2.2
The frameworks have some parts that overlap, but Semantic UI has more components that can
be easily used. There are tons of examples, plug-ins and snippets of code for Bootstrap, but
sometimes they do not match your current layout, or become deprecated with new releases.
This was the main reason for using Semantic UI instead of Bootstrap. Coincidentally, the next
major change in Speak Like A Brazilian is adding semantic web tags to the site. These tags are
useful for search engines, for displaying extra information in search results, but also for
linked data sites to index our content.
Nikto is a web server scanner, written in Perl and licensed under
GNU GPL. The source code is available at GitHub.
We released a new version of Speak Like A Brazilian last week,
upgrading from Laravel 4.x to 5.x. Once we had a release candidate (RC) tag
ready we deployed it and ran Nikto to check for issues in the server.
The default settings are enough for an initial test, but you can take a look at
nikto —help for other interesting parameters.
nikto -host https://speaklikeabrazilian.com
Here are the results of the scanning.
- Nikto v2.1.4
---------------------------------------------------------------------------
+ Target IP: 45.56.78.89
+ Target Hostname: speaklikeabrazilian.com
+ Target Port: 80
+ Start Time: 2016-04-08 12:57:02
---------------------------------------------------------------------------
+ Server: nginx
+ Retrieved x-powered-by header: PHP/5.5.9-1ubuntu4.14
+ No CGI Directories found (use '-C all' to force check all possible dirs)
+ robots.txt contains 11 entries which should be manually viewed.
+ ETag header found on server, fields: 0x5704861f 0xef
+ OSVDB-3092: /new: This may be interesting...
+ OSVDB-3092: /new/: This might be interesting...
+ OSVDB-3093: /.htaccess: Contains authorization information
+ OSVDB-3092: /de/: This might be interesting... potential country code (Germany)
+ OSVDB-3092: /it/: This might be interesting... potential country code (Italy)
+ OSVDB-3092: /jp/: This might be interesting... potential country code (Japan)
+ OSVDB-3092: /pt/: This might be interesting... potential country code (Portugal)
+ OSVDB-3092: /es/: This might be interesting... potential country code (Spain)
+ 6448 items checked: 39 error(s) and 11 item(s) reported on remote host
+ End Time: 2016-04-08 13:29:41 (1959 seconds)
---------------------------------------------------------------------------
+ 1 host(s) tested
There list had a few false positives, but two outstanding issues could be easily fixed.
First the .htaccess file.
And the second one is to hide the PHP server signature.
# File: php.ini# From: http://www.techbrown.com/hide-server-signature-of-nginx-php-version-on-linux.shtmlexpose_php= Off
It is not polite to run Nikto (or most other scanners to be honest) on web sites that you
do not maintain. Some sites are behind firewalls and IDS (Intrusion Detection System) systems
that may block Nikto. When that happens, you can liaise with your Ops team and schedule an
internal run on an application you develop or maintain.
Nikto may help you finding flaws in your server and deployment. The next step now for Speak Like A
Brazilian now is running the new code through
OWASP’s ZAP Proxy,
which can analyse the HTTP requests for possible bugs.
One of the most common tasks in data management, common in many companies, is
ETL. ETL stands for
Extract, Transform, and Load. Basically, it consists in retrieving existing data, doing
some transformation (remove columns, add columns, sum values, etc), and then loading the result
data back in to some other database.
We just finished migrating Speak Like A Brazilian from
Laravel 4.x to Laravel 5.x, and besides the necessary changes for adapting the existing code to
the new version of the framework, we have also tackled other issues in the backlog,
such as SSL, using a new e-mail service and a few changes in the database schema. Due to this
last item, we had to do a small ETL.
Talend Open Source Data Integration
You can download the free and Open Source
Talend Open Studio for Data Integration.
After installing it, you can read the documentation or watch some videos with short
tutorials.
Talend
But the interface can be quite intuitive, with drag and drop items, help pop up dialogue boxes, and
a help available with the local tool. There are other tools such as Luigi and Pentaho Kettle that could
have been used for the same task. It also supports several databases out of the box.
Talend has other free and commercial tools, that can be used for other tasks and processes in
Data Management, and solutions that can also work with Big Data.
On Using Docker
Since the database is quite small (< 10 MB), using Docker seemed like a good idea to avoid
installing MySQL or MariaDB locally and having to configure databases and move data around.
But before starting containers, we needed a dump of the existing database.
mysqldump -u user -p pass > slbr_20160403.sql
And now we could load the data into a new container, using the mysql:latest Docker image.
Transfer the data from the server to local computer, and start a container where we will store and massage the data.
Then we need to jump into that container to run a few commands to load the data.
docker exec -ti slbr /bin/bash
mysql -uroot -p -e "create database slbr"
mysql -uroot -p slbr < /opt/data/slbr_20160403.sql
Finally, make sure the application new database is ready as well.
It is already using Docker Compose,
so all it takes is start the containers with the following command:
docker-compose up
And then create the database structure with initial data.
Done, now the old database is running in one container of the mysql:latest image, listening to port 4406
and the new database is running with Docker Compose, listening for connection on 3306.
Creating Talend jobs to migrate the data
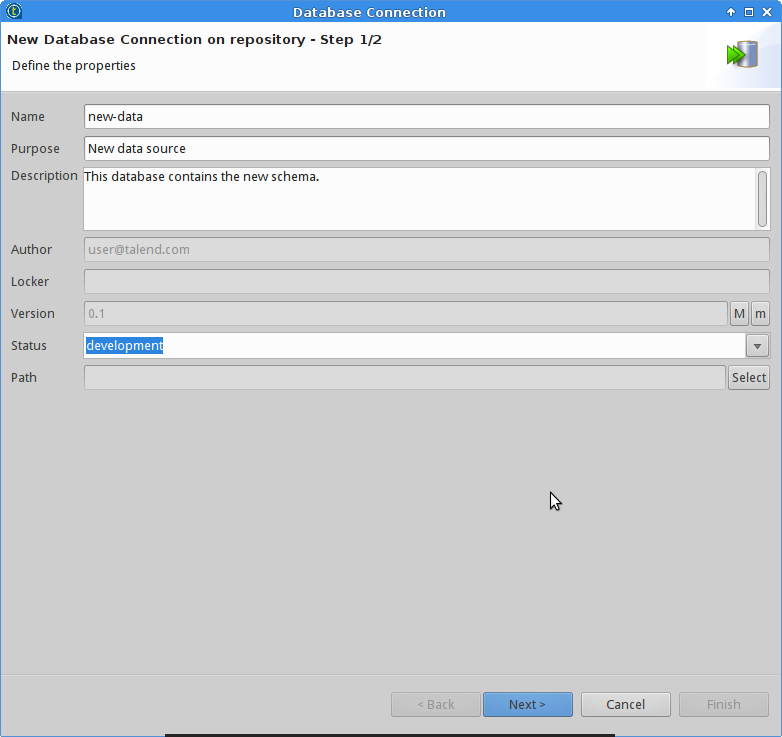
We start by creating a blank project in Talend.
ETL with Talend and Docker
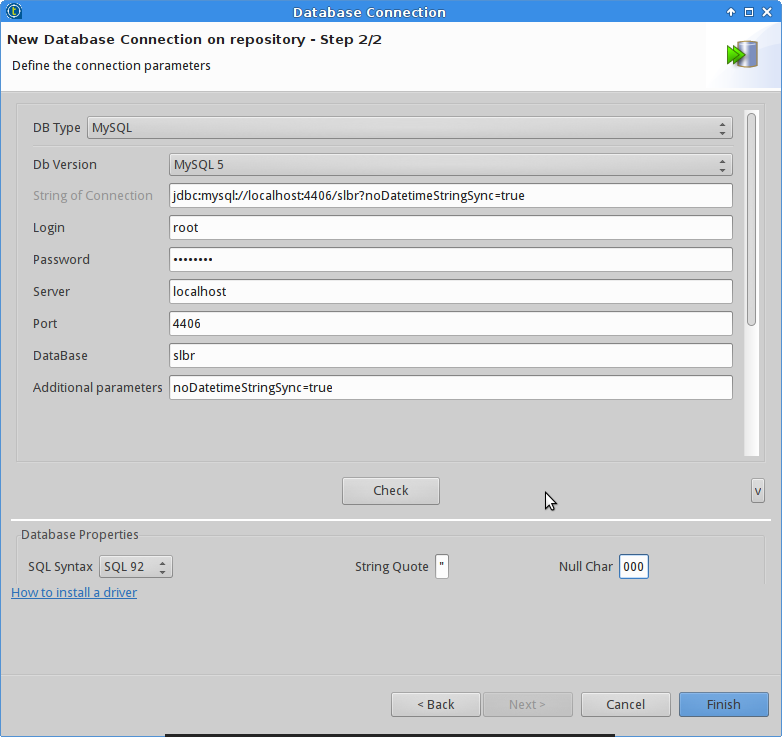
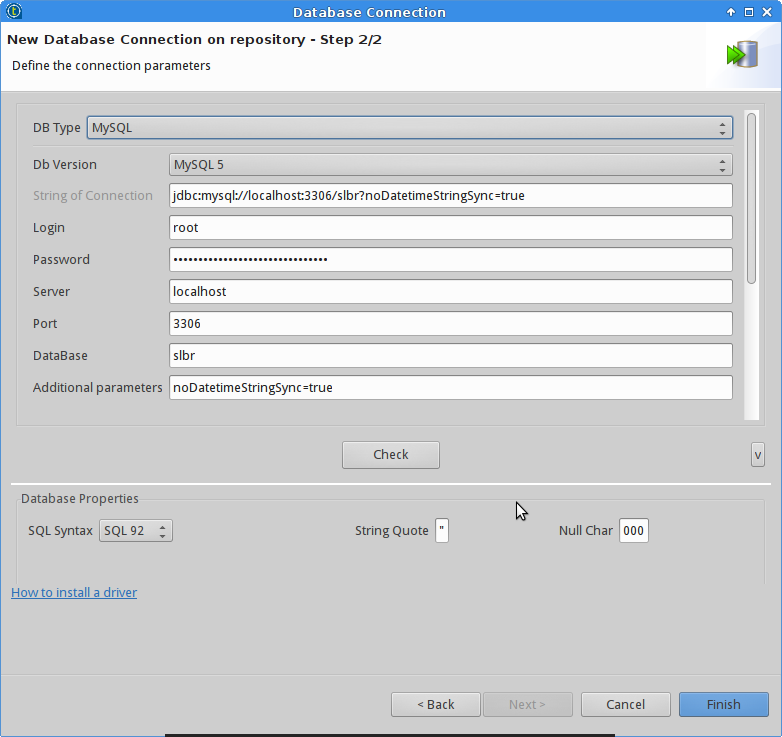
And then creating the database connections for the two databases.
ETL with Talend and Docker
ETL with Talend and Docker
ETL with Talend and Docker
ETL with Talend and Docker
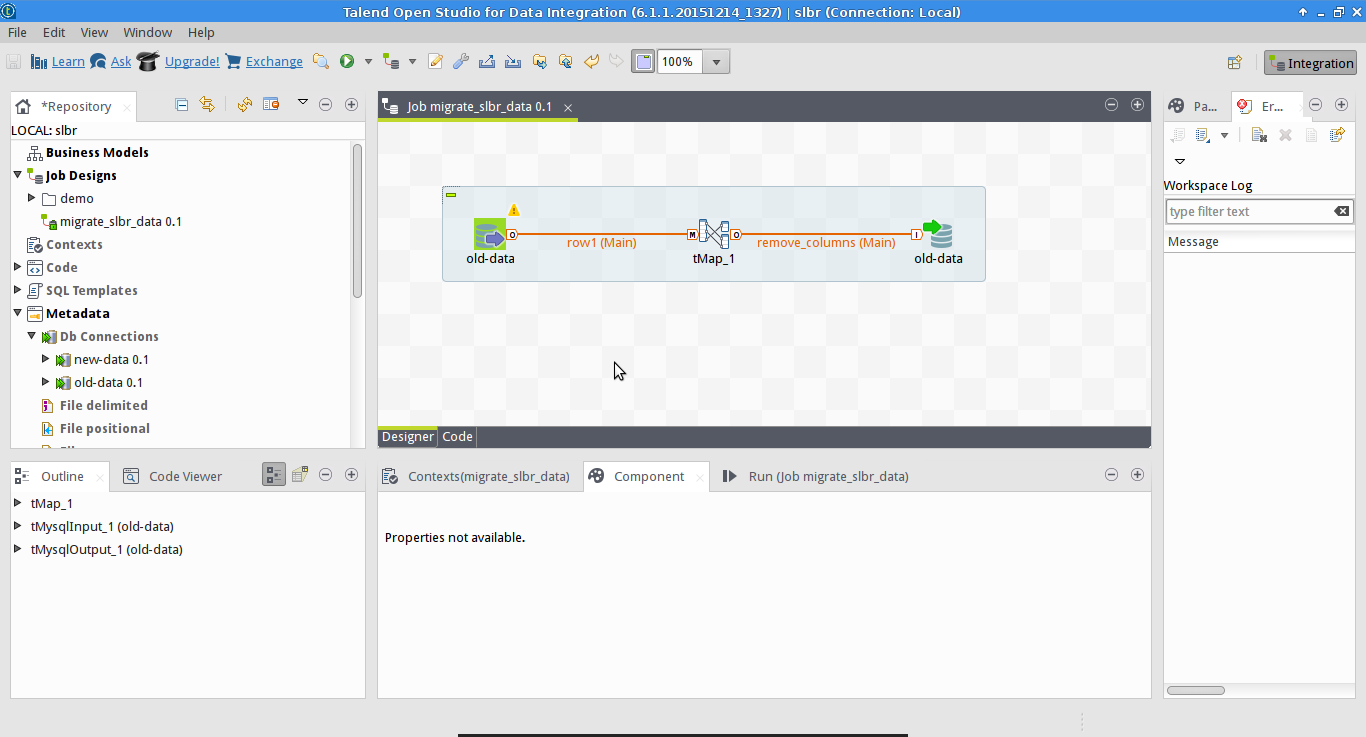
Now it is just a matter of dragging and dropping the two connections on to the main canvas.
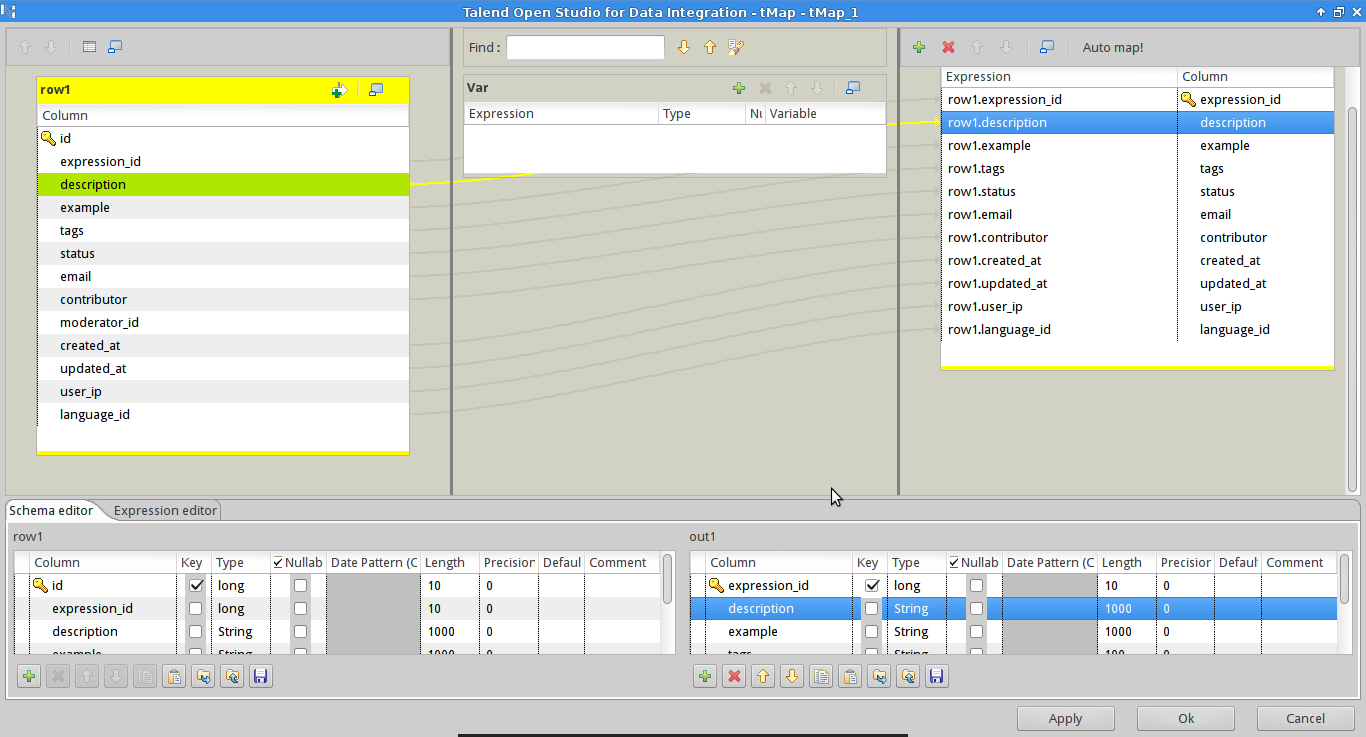
After that, we still need one more component: a map or
tMap. This allows you to map
columns between databases, doing transformations like running SQL functions or Java code.
ETL with Talend and Docker
ETL with Talend and Docker
In our case, the database for Speak Like A Brazilian had a few columns removed. These columns
were simply not mapped into the destination database. Running the job loaded the data, but excluding
the old columns.
There was also one column added with a default value, for which the tMap was also used.
You can play with Talend, use row filters and other components to do different data modifications,
and also use other features such as job schedule or combine with other Talend tools.
We could have used Python, Shell, or other tools for the job, but using a tool tailored for
ETL is quite handy and easy. Specially in case you ever need to do that again, against different
databases. All it takes is just adjust the database connections and re-run the jobs.
Separation of concerns is a design principle, and
states that each part of a software addresses a separate concern. Different patterns and abstractions
can be used for that like MVC, DAOs and repositories.
Repositories help in the abstraction of the data layer. It provides an interface for retrieving data,
independent of the implementation, acting like a collection of objects.
In Nestor-QA I had implemented repositories using some Java code I had in my
mind, without paying too much attention to the abstraction layers. Two weeks ago, while working on some
complicated issue in Nestor I noticed that the repositories in Nestor had been implemented using the
Eloquent classes.
Eloquent is a library used in Laravel for data abstraction. It provides access to databases like MySQL
and SQLite, kind like DAOs (and sometimes like repositories too). However, for Nestor being a test
management tool, we are trying to be platform and framework independent. Here’s the old repository code in
action:
class DbProjectRepository implements ProjectRepository { public function all() { return Project::where('project_statuses_id', '<>', 2)->get(); } // ...}
As you can see, we were returning the result of the get() method from Eloquent. Another big mistake was
using these objects in the views. In the end we were not only using data layer elements in the wrong place,
but we also had many queries to render an UI.
abstract class DbBaseRepository extends BaseRepository { protected $model; public function __construct($model) { $this->model = $model; } public function all() { return $this->model->all()->toArray(); } // ...}
After searching for a while, I found a nice example
of a class design for repositories, where the return type is always an array. In the views you will
have the array and keys, and in case someday you decide moving to another framework, you can leave the
views unchanged (hopefully :-). Neat, no?