Simple ETL with Talend and Docker for a Laravel website
A couple of years ago when I worked at a credit bureau, I learned how important Data Management is for a company. There are several processes involved in data management, such as Record Linkage, Data Cleansing, Master Data Management among others.
One of the most common tasks in data management, common in many companies, is ETL. ETL stands for Extract, Transform, and Load. Basically, it consists in retrieving existing data, doing some transformation (remove columns, add columns, sum values, etc), and then loading the result data back in to some other database.
We just finished migrating Speak Like A Brazilian from Laravel 4.x to Laravel 5.x, and besides the necessary changes for adapting the existing code to the new version of the framework, we have also tackled other issues in the backlog, such as SSL, using a new e-mail service and a few changes in the database schema. Due to this last item, we had to do a small ETL.
Talend Open Source Data Integration
You can download the free and Open Source Talend Open Studio for Data Integration. After installing it, you can read the documentation or watch some videos with short tutorials.

But the interface can be quite intuitive, with drag and drop items, help pop up dialogue boxes, and a help available with the local tool. There are other tools such as Luigi and Pentaho Kettle that could have been used for the same task. It also supports several databases out of the box.
Talend has other free and commercial tools, that can be used for other tasks and processes in Data Management, and solutions that can also work with Big Data.
On Using Docker
Since the database is quite small (< 10 MB), using Docker seemed like a good idea to avoid installing MySQL or MariaDB locally and having to configure databases and move data around.
But before starting containers, we needed a dump of the existing database.
mysqldump -u user -p pass > slbr_20160403.sql
And now we could load the data into a new container, using the mysql:latest Docker image.
Transfer the data from the server to local computer, and start a container where we will store and massage the data.
docker run -p 4406:3306 -v $PWD/Downloads/slbr:/opt/data -v $PWD/Development/php/workspace/speaklikeabrazilian.com/:/opt/slbr --name slbr -e MYSQL_ROOT_PASSWORD=nosecret -d mysql:latest
Then we need to jump into that container to run a few commands to load the data.
docker exec -ti slbr /bin/bash
mysql -uroot -p -e "create database slbr"
mysql -uroot -p slbr < /opt/data/slbr_20160403.sql
Finally, make sure the application new database is ready as well. It is already using Docker Compose, so all it takes is start the containers with the following command:
docker-compose up
And then create the database structure with initial data.
docker exec -ti speaklikeabraziliancom_front_1 /bin/bash
php artisan migrate:install
php artisan migrate:refresh --seed
Done, now the old database is running in one container of the mysql:latest image, listening to port 4406 and the new database is running with Docker Compose, listening for connection on 3306.
Creating Talend jobs to migrate the data
We start by creating a blank project in Talend.
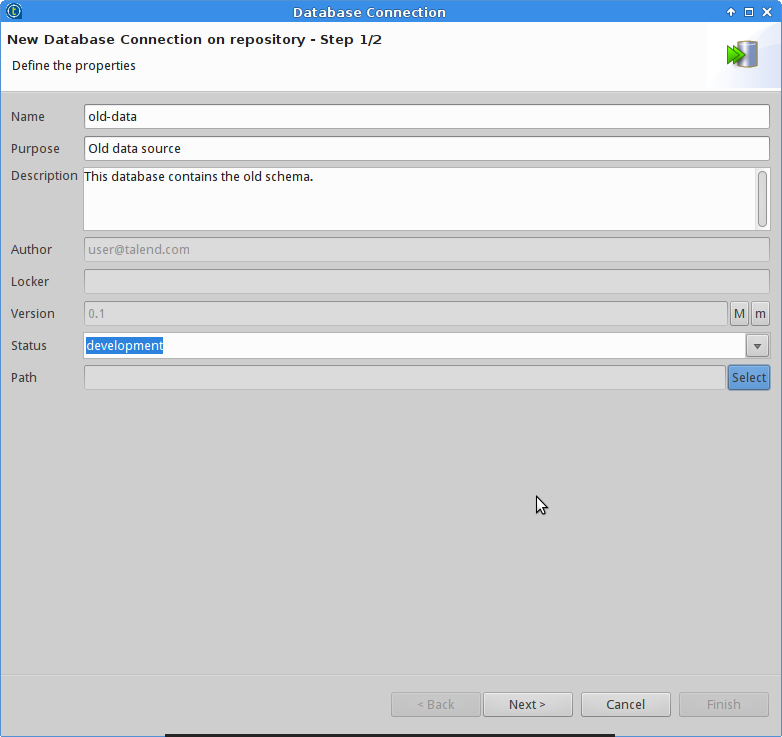
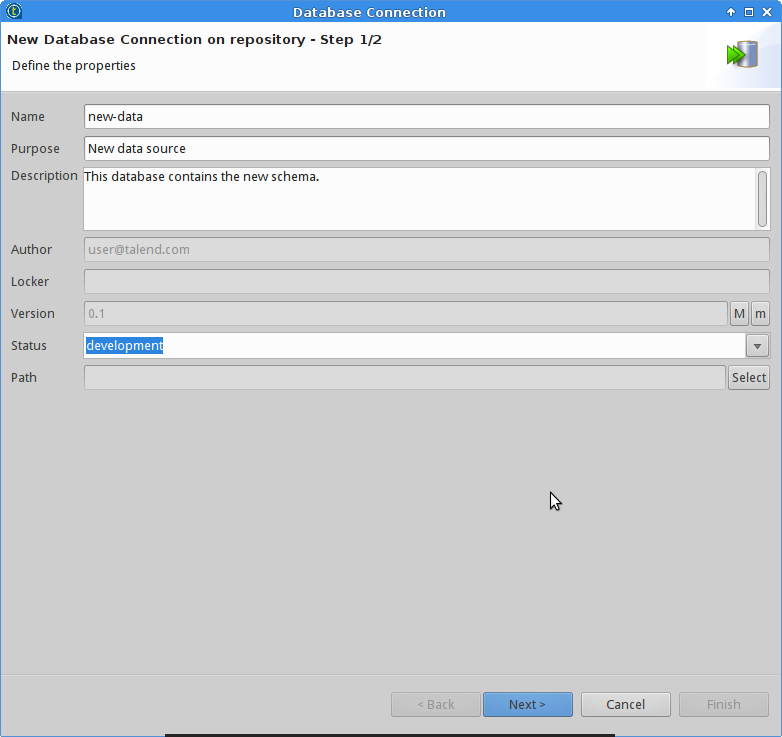
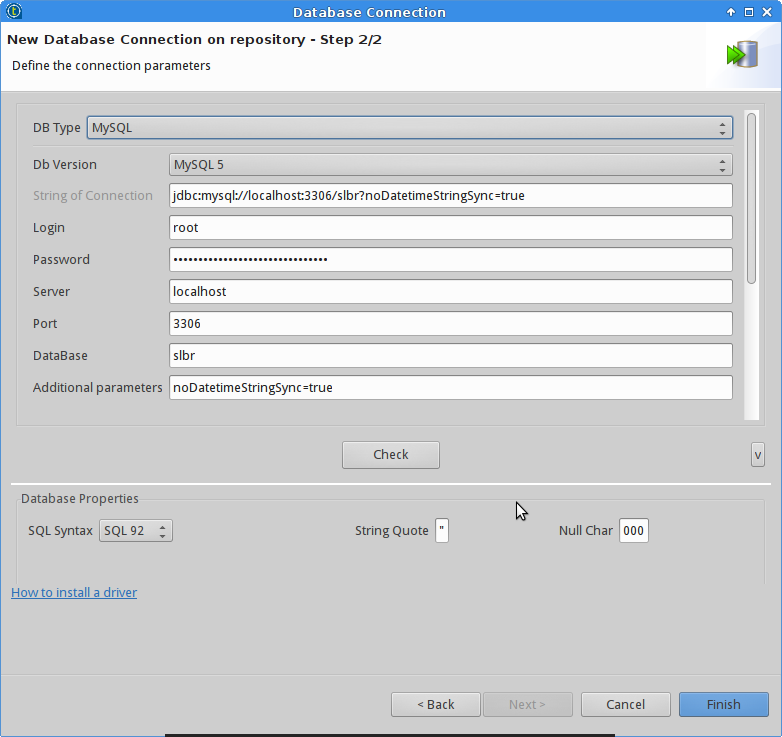
And then creating the database connections for the two databases.
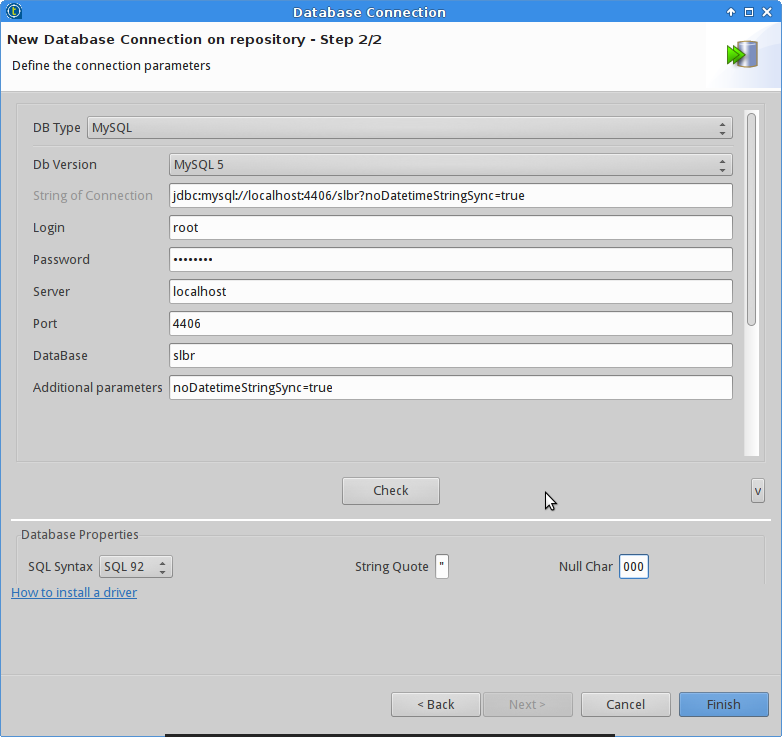
Now it is just a matter of dragging and dropping the two connections on to the main canvas. After that, we still need one more component: a map or tMap. This allows you to map columns between databases, doing transformations like running SQL functions or Java code.
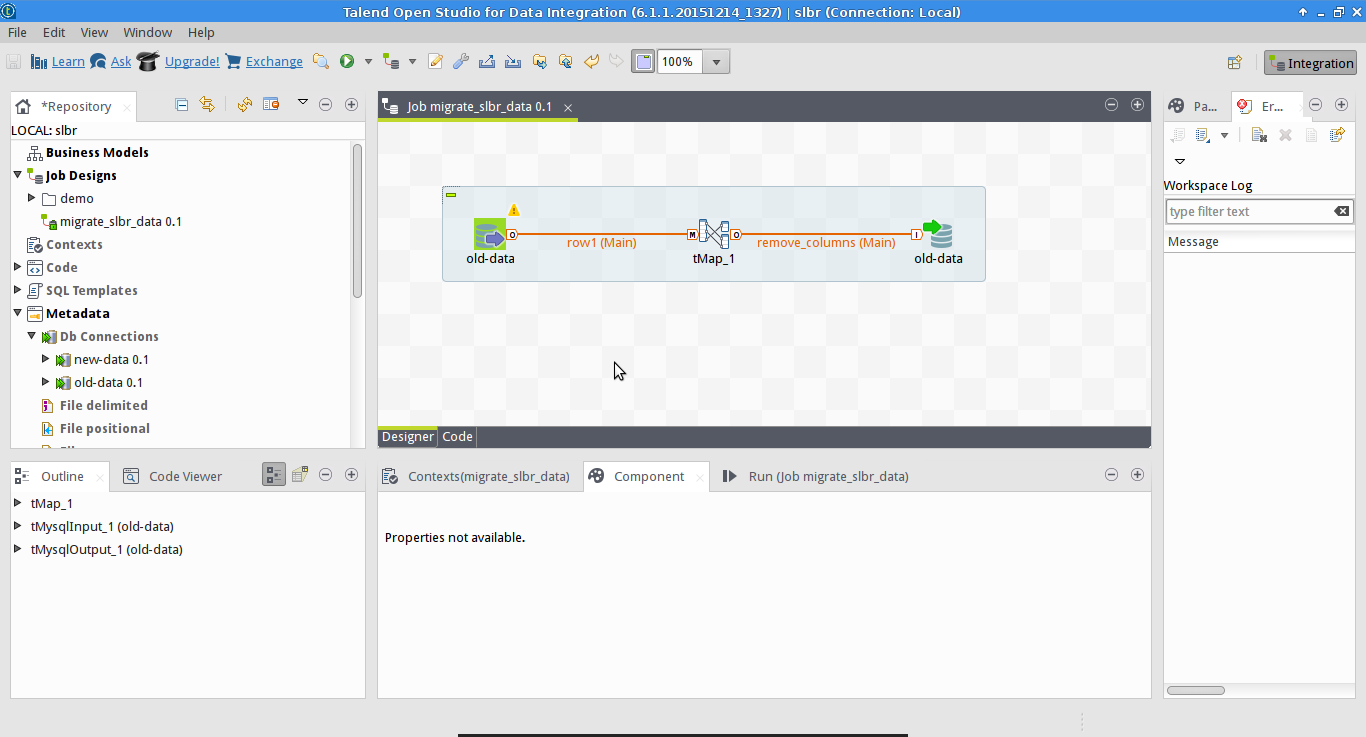
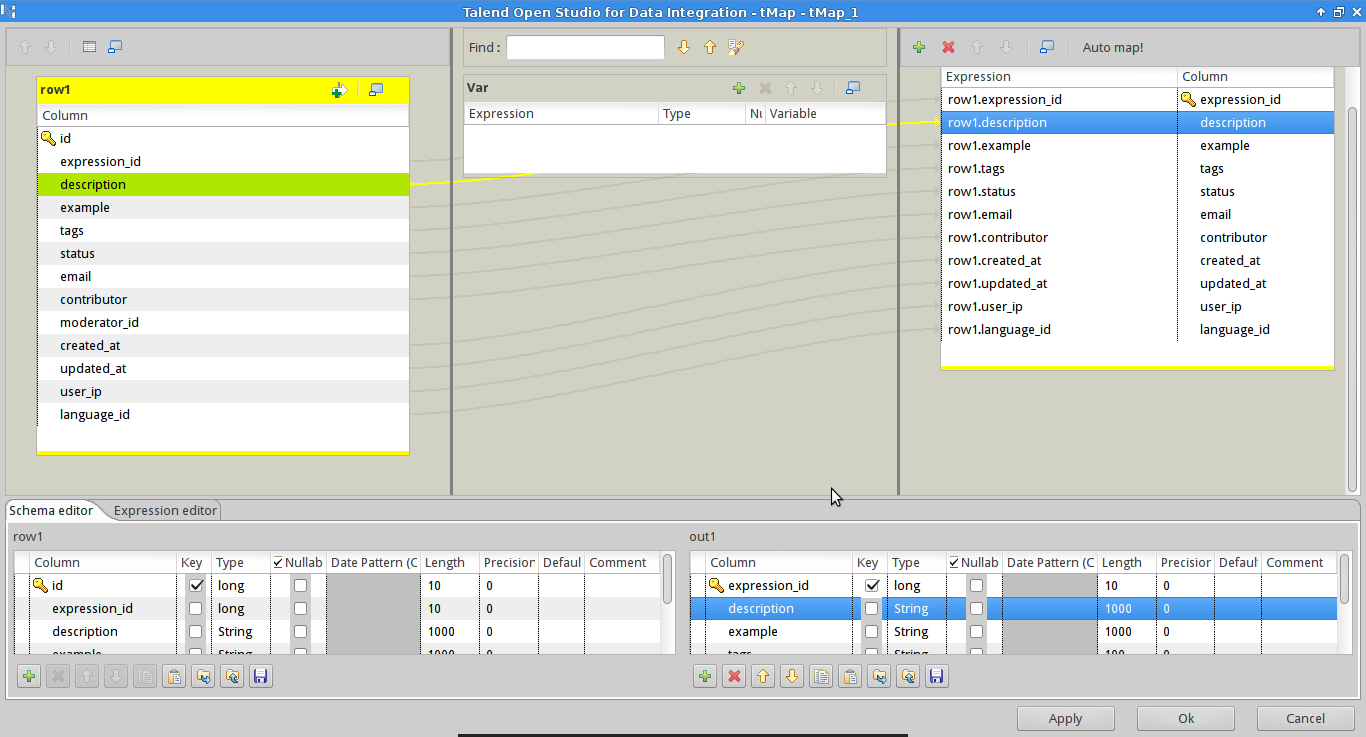
In our case, the database for Speak Like A Brazilian had a few columns removed. These columns were simply not mapped into the destination database. Running the job loaded the data, but excluding the old columns.
There was also one column added with a default value, for which the tMap was also used.
You can play with Talend, use row filters and other components to do different data modifications, and also use other features such as job schedule or combine with other Talend tools.
We could have used Python, Shell, or other tools for the job, but using a tool tailored for ETL is quite handy and easy. Specially in case you ever need to do that again, against different databases. All it takes is just adjust the database connections and re-run the jobs.